
Git and GitFlow
Git is used in software development projects of every kind. It has almost completely replaced earlier source code management tools such as CVs and Subversion. At the same time, it uses concepts that are difficult to understand.
Learning to use its many commands takes time, even for skilled developers. This piece doesn’t try to be a tutorial on using Git. Several good introductions for users are available. Here we’ll look at what Git does and how it organizes code that developers are working on. This will include a look at the GitFlow paradigm, a way of organizing Git workflows which have become widely popular. Anyone who wants to learn to use Git or understand it from a manager’s viewpoint needs to learn these concepts before plunging deeply into the commands.
The Basics of Git
The most important point is that Git is a distributed repository. Subversion and other earlier tools used a single, centralized repository. All developers checked their code out from the repository, made changes, and checked it back in. The repository allowed multiple branches, but they all resided on a central server.
Git lets each developer have their own copy of the remote repository. They clone it from the remote repository, make changes, and commit to their local copy. When they’re ready, they push their version of the repository to the remote. At any time, they can pull from the remote so that they’re up to date with changes that others have committed.
The local repository is a full copy of the remote one or one or more of its branches. It contains the full history of the branches, not just the latest version. A developer can create a new local branch, work in it, and merge back to the main branch before pushing to the remote repository.
Beginning to Use Git
When starting to use Git, a developer should customize it with the git config command. At a minimum, the configuration should have the developer’s name and email address, so that any changes that are checked in will be identifiable. It should also be set to ignore bookkeeping files which the operating system creates, so they won’t accidentally be added.
Developers need to know some basic commands to do this much. GUI tools for Git are available, but anyone who’s serious about it knows how to use it from the command line. Some of the first commands they’ll learn are:
- Git clone — Creates a local copy of a repository, and sets it up so that the developer can push and pull between the local repository and the remote.
- Fetch — Updates the local repository to match the remote.
- Pull — Updates the local repository and the working files.
- Push — Sends changes from the local repository to the remote. The changes are merged only if a “fast forward” merge is possible, meaning no one has made independent changes in the meantime. The preferred approach is to merge with the latest changes before pushing.
The Three Trees
A developer’s machine contains three places where files from Git are stored. They’re called the “three trees.” Understanding them avoids a lot of confusion in how Git processes changes.
- The HEAD in the local repository. The developer is always working in a particular branch, called the HEAD, at any moment. It contains files as they were pulled or fetched from the remote, or as the developer last committed them. A push will send the latest HEAD changes to the remote.
- The index. It stands between the working directory and the HEAD, and beginners tend to forget it’s there and not understand why their changes aren’t being committed. The developer needs to add files to the index before committing them.
- The working directory. The files here are available to edit, compile, or run. The developer can make any amount of changes, test them, and throw them away without affecting the index or HEAD.
To move edited files into the index, the developer uses the git add command. Only then is it possible to move them to the HEAD, using git commit.
GitFlow
Managing source code for regular releases requires being able to work on features separately from one another and not letting versions collide. The GitFlow process is a popular way to do this. A team can use it without any extra tools, though a package of extensions is available to simplify its steps.
The central repository uses two permanent branches. One is the usual Master; the other is the Develop branch. The Master branch is used for nothing except the production code. A code is checked into Develop before going to Master.
Each feature which developers are working on gets its own branch. They branch off from Develop, not from Master. The work on the feature is done in its own branch, then it’s merged into Develop.
Moving on to Production

When it’s time to move to production, a release branch is forked from the Develop branch. It shouldn’t get any major new code, but it’s where any remaining bug fixes and documentation enhancements will take place. When it’s ready to go, it’s merged back into Develop as well as Master. The current state of Master is tagged with a name of the form “release-x.y”. This is the code that goes to production. New work on the next release can then start by pulling code from Develop.
Sometimes it’s necessary to fix code after it’s been released. In the GitFlow model, this is called a “hotfix.” Developers can create a hotfix branch for this purpose. Only hotfixes branch directly from Master. After making the necessary changes, they check the hotfix back into Develop and Master. The fixed version is tagged with a patch release number, using the form “hotfix-x.y”.
Developers can make feature branches, but only team leaders should create release branches. Leaders should also handle all merging into Develop and Master.
GitFlow isn’t the only workflow that’s possible with Git, but it’s effective in coordinating large projects.
Learn More About Git
Authoritative documentation on Git is available on git-scm.com. A free ebook, videos, and pages on individual commands are available. The help pages on GitHub are another useful resource, especially for developers using GitHub as their primary repository. Codecademyoffers a free introductory course.
Managers who deal with software teams need to understand the language of Git, even if they don’t personally use it. Knowing what it’s all about will help in understanding and planning development and release processes.
There’s always more to learn. The team at Entrance Consulting puts on regular “brown bag” lunch sessions where a team member leads a discussion on a chosen topic. The subject could be tools, languages, or the art of dealing with emergencies. Everyone contributes from their own experience. Participants talk not only about the technology but the real-world issues involved in using it. This makes us keep our own skills sharp, so we can better serve our clients.

AWS Lambda and Azure Functions: Use Cases and Pricing
AWS Lambda & Azure Functions
Amazon’s AWS Lambda and Microsoft’s Azure Functions are very similar in many ways. They’re both FaaS (functions as a service) or “serverless” services. They have similar pricing models and support many of the same languages. Still, there are significant differences between them, which could influence which one is better for your needs.
The most basic difference is the underlying operating systems. Lambda, like most AWS services, runs on Linux. Azure Functions runs on Windows. Perhaps this shouldn’t matter in a serverless environment, but you’ll normally want to call other services from your functions, and the available choices reflect the underlying software. The operating system environment affects many aspects of deployment, configuration, and debugging. If your development team has a strong commitment to one operating system or the other, that could make a difference.
Lambda was launched in 2014, Azure Functions in 2016. Lambda is ahead in market share and has an edge in maturity and stability, though Azure Functions isn’t far behind.
AWS Lambda vs. Azure Functions: Pricing
The pricing models for both services are similar, and there’s very little difference in how much you pay. In both cases, the cost is based on two factors: the number of function invocations and the number of gigabyte seconds used. With Azure, you pay $0.20 per million executions, plus $0.000016 per GB second. The first million executions and first 400,000 GB seconds are free. There’s no charge while the code is lying idle between executions.
With Lambda, prices are so close that they’re obviously watching each other. The first 400,000 GB seconds are free, a million requests cost $0.20, and GB seconds are a shade more expensive at $0.00001667.
In both cases, storage is a separate service, which you have to pay for. Functions don’t maintain any persistent storage or state by themselves.
It’s possible to pay for Azure Functions under an Azure App Service plan, but that approach is more like a PaaS model. A VM is dedicated to your functions, and you pay to keep it. For this article, we’re comparing the serverless offerings. The one for Azure Functions is called the Consumption plan.
AWS Lambda & Azure Functions: Design Differences
The basic FaaS concept is the same for both services. The developer creates and deploys functions. Events invoke or “trigger” them. Calling them by HTTP is the most common scenario. But there are differences in the elaboration of the concept.
In Lambda, each function is a separate unit. You can install any number of functions in a single operation, but each one has its own environment variables. You can build applications out of them, to a limited extent, with AWS Step Functions, which implement a state machine.

The only way to deploy software to Lambda is to upload a zip file with the code. In an automated development process (such as we use at Entrance), this is a transparent step. Azure Functions offers a richer set of deployment options, including integration with code repositories such as GitHub and Bitbucket. On the other hand, Lambda supports versioning of functions, which isn’t available with Azure.
AWS Lambda and Azure Functions: Supported Languages and Environments
The choice of languages could be an important factor in choosing between the services. Microsoft’s service supports C#, JavaScript (Node.js), and F#. It lists other languages as “experimental,” including Python, PHP, TypeScript, Bash, and PowerShell. Java is in the works.
Lambda lists JavaScript (Node.js), Python, Java, C#, and Go as its supported languages. Developers on Lambda can use .NET Core, so they aren’t completely divorced from the Microsoft world.
The biggest difference is in the associated services which are available. With Lambda, developers can use S3 storage, use Elastic Beanstalk and EC2 where virtual machines are necessary, and access databases through RDS. Azure functions developers will use Azure Storage, supported databases such as Azure SQL, and Windows or Linux virtual machines. Each environment has its own flavor, and AWS has the greater breadth of services. For many developers, familiarity with the available services may be as important as their inherent technical qualities.
Kinds of applications in AWS Lambda and Azure Functions
Leaving aside support for languages and services, the most important difference between these two FaaS services is the organizational philosophy.
Azure’s function apps encourage thinking of the “application” as the unit. The configuration files apply to the whole app, and resources are allocated to a function app. Lambda promotes a more atomistic approach, with each function being its own entity and getting its own resources. This could encourage an approach in Lambda where each function is largely independent of the others, while Azure Functions may promote an approach where the functionality overlaps heavily. However, both allow calls to libraries, objects, and subroutines from top-level functions, so there really isn’t that much difference. For more discussion of the differences, see our introduction to AWS Lambda.
Each service has a distinct approach to triggering functions. Azure is somewhat simpler, while Lambda’s approach is more versatile.
The important distinctions are going to be in the language which the developers prefer (if it’s only available on one of the services) and, above all, the related services which are available. Amazon has the advantage here, with a powerful set of services that Lambda functions can invoke.
Let’s say you want to implement a system to retrieve and update information in an employee database. It will process requests from a Web page, with each request type being a function. Only authorized users can access it, so it will use AWS Identity and Access Management or Azure Active Directory for authentication. It will need access to a database server. Azure strongly encourages the Microsoft SQL Database, while AWS offers a variety of database software. It works either way, but AWS often offers more options.
Are you looking to set up services in AWS? Get in touch with us to learn how we can help.
About Microsoft Silverlight
Silverlight is a Rich Internet Application framework developed by Microsoft. Like other RIA frameworks such as Adobe Flash, it enables software developers to create applications that have a consistent appearance and functionality across different web browsers and operating systems. Silverlight provides users with a rich experience, with built-in support for vector graphics, animation, and audio and video playback.
Although Silverlight is still a relatively new technology, it has already been used for live streaming of high-profile events such as the 2008 Beijing Olympics and the 2009 Presidential Inauguration. It is also being used by major sports organizations to broadcast live content.

The Landscape of Big Data Analytics and Visualization
Are you considering which of the big data analytics and visualization tools will work best for you? For our money, Tableau is leading the pack. However, there are several competitors who offer some interesting options. Here is a look at a few of those.
Please keep in mind this is a high-level sampling of capabilities mostly pulled from company websites and customer feedback where we can find it. This is not meant to be an in-depth study of features or a recommendation as to which tool would best meet your needs.
To get that, you’ve got to invest in a disciplined software selection process, something that we highly recommend prior to investing in a new tool that will play an important role in your business.
Sisense
When thinking about big data analytics and visualization tools, one of the first that comes to my mind is from Sisense. Sisense boasts an in-chip technology that is best in its class as an analytics engine and is 10 to 100 times faster than in-memory technology. It goes through terabytes easily and eliminates the need for data prep work. You simply access your info through any data source, drag and drop the data you want to see, and clean up the data you no longer need after you’re done. The Sisense tool allows you to turn data into usable data that can be instantly managed, allowing you to change or add data sources. Some of the things you can do with Sisense include:
- Instantly blending large amounts of data.
- Analyze data without the need for hard coding, aggregating, or remodeling.
- Unlock analytics with instant response time and smarter shortcuts.
- Receive automatic alerts for your most important KPIs.
- Choose a deployment strategy that works for you, including on-premises, cloud, or hybrid. Sisense provides managed service, as well.
- Secure your data with comprehensive controls.
Sisense users are pleased with the way they’re able to take millions of lines of data, even from multiple social networks, and put it all together into one comprehensive information package. Additionally, users have commented that they like how Sisense’s software allows anyone to collect and manage data, even if they’re not a technology expert.
QlikView
With its Associative Difference tool, Qlik offers a way to explore your data without limiting you to query-based, linear exploration like other modern BI tools do. According to the Qlik website, QlikView’s Associative Difference enables you to:
- Search and explore data analytics in any direction.
- Gain quick insights with interactive selections.
- Combine all your data insights, regardless of their size.
- Calculate and aggregate with a single click.
- Index all data relationships to find insights you wouldn’t catch on your own.
- Rapidly build and deploy analytic apps.
- Control analytic apps, permissions, and data with strong security.
- Customize the exact tools you need for your organization.
- Use global search to accelerate discovery.
- Create consistent reports and templates.
Qlik has been providing its technology for a while, but remains in the pack of possibilities for the up-to-date data analytics and visualization tool you need. The company states that its mission is to provide people, businesses, organizations, and government with the ability to explore and share all of the data that is available to them in a single platform.
Dundas BI
The Dundas BI platform looks a lot like Tableau to me. It has some cool features, including a data pipeline that allows various types of users to start their exploration of the data in accordance with their preferences. In addition, any content that a user creates may be shared and used across the entire organization. Some of the other features that Dundas BI offers include:
- The use of modern HTML5 and fully open APIs to customize and meet your users’ design requirements.
- The ability to connect, interact, and analyze data from any device, even mobile devices.
- A wide range of visualizations and layout options.
- Highly customizable visualizations, including interactive charts, gauges, scorecards, and maps.
- The ability to run ad-hoc queries and quickly create reports and dashboards.
- Drag-and-drop functionality to add your own data files.
- Automatic data preparation and smart defaults to make quick work of your collection.
- One-click setup of a wide range of statistical formulas and period-over-period comparisons that is done directly on your visualizations in order to provide you with instant results.
Users of Dundas BI say that the product is flexible, dynamic, and easy to use.
Offerings From Companies You Already Know

In addition to the three alternatives discussed above, a number of companies you already know and have experience with also offer an array of BI tools that may be what you need. Here are some suggestions to look at:
- SAP: SAP Analytics Cloud provides simple cloud deployment, collaborative enterprise planning, advanced predictive analytics and machine learning, response to natural language queries, and the ability to easily model complex queries. Intuitive self-service features allow users to easily explore information from across the organization.
- IBM Cognos: IBM Cognos allows for smart exploration that uses machine learning and pattern detection to analyze data. Additionally, it provides automated visualizations, storytelling capabilities that can be enhanced with media, web pages, images, shapes, and text. Content can be re-used from existing dashboards and reports. Predictive analytics provide users with the ability to identify key patterns and variables and natural language insights.
- Oracle Analytics: Oracle states that its Analytics offering provides faster insights without the need for help from IT. Additionally, it offers collaboration features for analytics that are both shareable and traceable. In its fourth year since becoming available to the general public, Oracle recently refreshed its data visualization tool with autonomous analytics to help users find and compile compelling stories that are powered by machine learning.
- Microsoft Power BI: Microsoft states that its Power BI allows you to connect to hundreds of data sources, prep the data, and create beautiful reports all in a matter of minutes. Millions of users worldwide are familiar with the Power Query based experience for data preparation, and the platform provides users with the ability to re-use their data preparation logic across multiple reports and dashboards. Users find the Power BI dataflows’ ability to handle large datasets to be an exciting new feature.
Learn More About Data Analytics and Visualization Tools
Your ultimate decision about which product you choose for your big data analytics and visualization needs depends on ease of deployments and use. Ultimately, it depends on which features are most important to you. Be sure during your research to check out the demos that these companies offer for a helpful glimpse as to how the product works. When you pick one, drop us a line and let us know which one you chose and why!

Seriously, Where Are All the Computer Idioms?
Idioms are far from uncommon throughout the technology industry. Whether you’re in software or hardware development or handle the business end of an IT company, you’re going to hear phrases such as kill two birds with one stone, bells, and whistles, everything’s running ship-shape, and in Layman’s terms, just to name a few.
These expressions are shorthand for the much more complex processes going on, keeping communications between developers quick and universal. Idioms also make it far easier to communicate what developers are handling to the business side of the company. Rather than trying to explain to the CFO how you’ve optimized application’s processes to reduce the amount of stress put on the device’s CPU, for example, you could just say, “Everything’s smooth sailing after this update!”
Despite the prevalence of shorthands, idioms, and expressions in the tech industry, you hardly ever hear any technology-based idioms. You wouldn’t ever necessarily hear, “That’s like blocking two DDOS attacks with one firewall” Rather, “This firewall kills two birds with one stone” would be the knee-jerk phrasing, even between two developers. Why?
Seriously, Where Are All the Computer Idioms?
Before boiling down where this shortage of computer and technology-based idioms stem from, it’s imperative to wrap your head around what an idiom is. Perhaps looking into their history will spare us a clue or two.
What is an Idiom?
An idiom is a figure of speech intended to express an idea other than it’s literal meaning. For example, if someone has cold feet, their feet aren’t actually cold (well, their feet maybe, who knows – but that’s not the point of the idiom), it means they’re unsure of a decision, event, etc…
The Idioms, the largest idiom dictionary on the internet, estimates that there are over 25,000 idioms in the English language alone. Common idioms include:
- a dime a dozen – the subject in question is common, just like any other.
- beat around the bush – to avoid something.
- cut me some slack – translates to “go easy on me”
- back to the drawing board – to start all over again.
- jump the gun – to get ahead of one’s self.
- let it off the hook – let it go.
- missed the boat – missed the opportunity.
- a grey-area – something unclear.
- a rip-off – something of much lesser value than it’s cost.
- break a leg – good luck.
- kill two birds with one stone – one solution solves multiple problems.
- ship-shape or smooth sailing – everything is working intended, without issue.
- bells and whistles – fancy upgrades.
- wrap my head around – come to understand something.
Idioms vary from culture to culture, but they exist within every language. Idioms you may hear all around the globe include:
- mustard after lunch – is a Polish expression to denote it’s too late.
- not all donuts come with a hole – is an Italian idiom that refers to disrespecting someone.
- to have dumplings instead of flowers – is a Japanese expression for picking something useful over something aesthetically pleasing.
- a whole lot of noise and no walnuts – is the Spanish version of all bark and no bite, an expression for someone who’s all talk without ever pursuing what they say.
Some idioms are far easier to decode than others. Missed the boat, and cut me some slack are pretty self-explanatory, but mustard after lunch might take a minute or two for someone who isn’t familiar with Polish culture to wrap their head around.

History of Idioms
While you could pinpoint the origins of specific idioms, it’s hard to nail down where the idea of idioms originated from. They have been so embedded and ingrained within our day-to-day language throughout societies around the world, you may as well say they’ve been around since the dawn of time.
Idioms can be traced all the way back to a time of Aesop, mid-6th century BCE. A Greek slave by the name of Aesop wrote 725 fables, which were relayed from one another with the intent to entertain and teach a moral lesson. More often than not, these fables revolved around animals or insects; foxes, grasshoppers, crabs, and stags.
In the fable The Fox and the Grapes, a fox dismisses the grapes he tried so hard to grasp as just sour grapes after being unable to reach them. Sour grapes have gone on to live outside of the fable itself as their own expression. More often than not, someone who is a sore loser may play indifferently to their shortcomings as “sour grapes”.
Although these expressions have been around for quite some time, the word idiom itself only arose sometime during 1588 in France, according to Merriam-Webster.
Memes and Idioms
In more recent years, memes have taken the world by storm. Similar to idioms, memes are intended to quickly represent an idea, typically with an air of humor. While a meme doesn’t necessarily have to be an idiom, many memes found themselves on sarcasm, existential humor, or exaggerations – they are not meant to be taken seriously.
Memes may also be an icon, figure, or image, such as the troll face, grumpy cat, or even popular phrases and hashtags.
The word meme itself was coined by an English ethologist and evolutionary biologist, Richard Dawkins. In a book he published in 1976, The Selfish Gene, Dawkins invents the word meme to express how information spreads and develops in culture.
Where are All the Computer Idioms?
Although idioms have been around for quite some time and they serve as the basis for memes in more recent years, there is still a serious lack of computer and technology-based idioms.
Which, unfortunately, makes sense. These expressions have been ingrained in our society for hundreds upon thousands of years, and the invention of the computer is far more recent.
According to Computer Hope, the first mechanical computer was invented in 1822 by Charles Babbage. The Z1, first programmable computer – a machine that closely resembles what we would refer to as a computer today, in contrast to Babbage’s invention – was invented by a German civil engineer by the name of Konrad Zuse.
Perhaps the explanation for the lack of technology is as simple as time.
Which leaves us to wonder… Will the computer-based idioms be the norm in future societies? Will younger generations still use and understand the colonial era expressions such as, you’ve got a screw loose, or it’s time to face the music, that we still use 300 years after their invention?
It’s definitely interesting to ponder.
Keep up with the latest in Software Development over on our blog. To learn more information about Entrance Consulting or schedule a software development consultation, please contact us.

AWS Lambda and Virtual Machines | Use Cases and Pricing
This article compares AWS Lambda and virtual machines, discussing when to use each and digging into pricing.
A virtual machine isn’t the only way to get computing power on AWS, and it isn’t always the most cost-effective. Sometimes you just need to set up a service that will perform a task on demand, and you don’t care about the file system or runtime environment. For cases like these. AWS Lambda may well be the better choice.
Amazon makes serious use of Lambda for internal purposes. It’s the preferred way to create “skills,” extended capabilities for its Alexa voice assistant. The range of potential uses is huge.
AWS Lambda and virtual machines both exist on a spectrum of abstraction wherein you take on less and less of the responsibility for managing and patching the thing running your code. For this reason, Lambda is usually the better bet when your use case is a good fit.
What is AWS Lambda
Note: For a full analysis breaking down what AWS Lambda is with pricing examples, see our earlier post, “What is AWS Lambda – and Why You’re About to Become a Huge Fan“.
Lambda is a “serverless” service. It runs on a server, of course, like anything else on AWS. The “serverless” part means that you don’t see the server and don’t need to manage it. What you see are functions that will run when invoked.
You pay only per invocation. If there are no calls to the service for a day or a week, you pay nothing. There’s a generous zero-cost tier. How much each invocation costs depends on the amount of computing time and memory it uses.
The service scales automatically. If you make a burst of calls, each one runs separately from the others. Lambda is stateless; it doesn’t remember anything from one invocation to the next. It can call stateful services if necessary, such as Amazon S3 for storing and retrieving data. These services carry their own costs as usual.
Lambda supports programming in Node.js, Java, Go, C#, and Python.
Comparison with EC2 instances
When you need access to a virtual machine, Amazon EC2 offers several ways to obtain one. It has three ways to set up an instance which is a VM.
On-demand instances charge per second or per hour of usage, and there’s no cost when they’re inactive. The difference from Lambda is that the instance is a full computing environment. An application running on it can read and write local files, invoke services on the same machine, and maintain the state of a process. It has an IP address and can make network services available.
Reserved instances belong to the customer for a period of time, and billing is for the usage period. They’re suitable for running ongoing processes or handling nearly continuous workloads.
Spot instances are discounted services which run when there is spare capacity available. They can be interrupted if AWS needs the capacity and will pick up later from where they left off. This approach has something in common with Lambda, in that it’s used intermittently and charges only for usage, but it’s still a full VM, with all the abilities that imply. Unlike Lambda, it’s not suitable for anything that needs real-time attention; it could be minutes or longer before a spot instance can run.

Use cases for Lambda
Making the right choice between AWS Lambda and virtual machines means considering your needs and making sure the use case matches the approach.
The best uses for Lambda are ones where you need “black box” functionality. You can read and write a database or invoke a remote service, but you don’t need any persistent local state for the operation. Parameters can provide a state for each invocation. Cases which this functionality could be good for include:
- Complex numeric calculations, such as statistical analysis or multidimensional transformations
- Heavy-duty encryption and decryption
- Conversion of a file from one format to another
- Generating thumbnail images
- Performing bulk transformations on data
- Generating analytics
Invoking a Lambda service is called “triggering.” This can mean calling a function directly, setting up an event which makes it run, or running on a schedule. With the Amazon API Gateway, it’s even possible to respond to HTTP requests.
AWS Step Functions, which are part of the AWS Serverless Platform, enhance what Lambda can do. They let a developer define an application as a series of steps, each of which can trigger a Lambda function. Step Functions implement a state machine, providing a way to get around Lambda’s statelessness. Applications can handle errors and perform retries. It’s not the full capability of a programming language, but this approach is suitable for many kinds of workflow automation.
AWS Lambda and Virtual Machines | Comparing costs
Check out Amazon’s pricing calculators for full details on Lambda pricing and EC2 pricing.
Like other factors when comparing AWS Lambda and Virtual Machines, Lambda wins out on cost if your use case supports using it.
Lambda wins on cost when it’s employed for a suitable use case and when the amount of usage is relatively low. “Relatively low” leaves a lot of headroom. The first million requests per month, up to 400,000 GB-seconds, are free. Customers that don’t need more than that can use the free tier with no expiration date. If they use more, the cost at Amazon’s standard rates is $0.0000002 per request — that’s just 20 micro cents! — plus $0.00001667 per GB-second.
The lowest on-demand price for an EC2 instance is $0.0058 per hour. By simple division, neglecting the GB-second cost, a Lambda service can be triggered up to 29,000 times per hour and be more cost-effective.
Many factors come into play, of course. If each request involves a lot of processing, the costs will go up. A compute-heavy service on EC2 could require a more powerful instance, so the cost will be higher either way.
Some needs aren’t suitable for a Lambda environment. A business that needs detailed control over the runtime system will want to stay with a VM. Some cases can be managed with Lambda but will require external services at additional cost. When using a virtual machine, everything might be doable without paying for other AWS services.
The benefits of simplicity
When it comes to AWS Lambda and virtual machines, it comes down to using the simpler method as long as it meets your needs. If a serverless service is all that’s needed, then the simplicity of managing it offers many benefits beyond the monthly bill. There’s nothing to patch except your own code, and the automatic scaling feature means you don’t have to worry about whether you have enough processing power. It isn’t necessary to set up and maintain an SSL certificate. That frees up IT people to focus their attention elsewhere.
With the Lambda service, Amazon takes care of all security issues except for the customer’s own code. This can mean a safer environment with very little effort. It’s necessary to limit access to authorized users and to protect those accounts, but the larger runtime environment is invisible to the customer. Amazon puts serious effort into defending its servers, making sure all vulnerabilities are promptly fixed.
With low cost, simple operation, and built-in scalability, Lambda is an effective way to host many kinds of services on AWS.

The Entrance ‘What, Why?’ Series: React Edition
Welcome to the ‘What, Why?’ series hosted by Entrance. The goal of this series is to take different technologies and examine them from a technical perspective to give our readers a better understanding of what they have to offer. The web is filled with tons of resources on just about anything you could imagine, so it can be really challenging to filter out all of the noise that can get in the way of your understanding. This series focuses on the two biggest cornerstones of understanding new tools: What is it, and why use it? So, without further ado, let’s kick off this first edition with something you’ve probably heard of: React!
React, quite simply, is getting big. It’s one of the most starred JavaScript Libraries on GitHub, so it goes without saying that it’s garnered lots of followers, as well as fanboys. React was originally developed by Facebook for internal use and many will be quick to point out that instagram.com is completely written with React. Now, it’s open source and backed by not just Facebook, but thousands of developers worldwide and considered by many to be the ‘future of web development’. React is still new-ish, but has had time to mature. So, what is it?
What is React?
A JavaScript Library
First and Foremost: React is a JavaScript Library. Even if some call it a framework, it is NOT. It is ONLY a view layer. What is the purpose of the library? To build User Interfaces. React presents a declarative, component-based approach to UIs, aimed at making interfaces that are Interactive, stateful, and reusable. It revolves around designing your UI as a collection of components that will render based on their respective states.
Paired with XML Syntax
React is also often paired with JSX or JavaScript XML. JSX adds XML syntax to JavaScript, but is NOT necessary in order to use React. You can use React without JSX, but having it would definitely help make things more clean and elegant.
‘Magical’ Virtual DOM
A distinguishing aspect of React is that uses something magical called ‘The Virtual DOM’. Conceptually, virtual DOM is like a clone of the real DOM. Let’s make the analogy of your DOM being a fancy schmancy new sports car of your choice. Your virtual DOM is a clone of this car. Now, let’s say you want to trick out your sweet new ride with some killer spinny-rims, wicked flames decals on the sides and, the classical cherry-on-top, a pair of fuzzy dice hanging from the rear-view mirror. When you apply these changes, React runs a diffing algorithm that essentially identifies what has changed from the actual DOM (the car) in your virtual DOM (your now-tricked-out clone). Next, it reconciles the differences in the Real DOM with the results of the diff. So, really, instead of taking your car and completely rebuilding it from scratch, it only changes the rims, sides, and rear-view mirror!
Why React?
Component Modularity
Now that we’ve got a reasonable understanding of what React is, we can ask: Why use it? One of the biggest pluses to React is the modularity caused by its paradigm. Your UI will be split into customizable components that are self-contained and easily reused across multiple projects; something everyone can appreciate. Not only that, but components make testing and debugging less of a hassle as well.
Popular Support
The popularity of React also plays to its advantage. Being fully supported by Facebook AND thousands of developers means there will be plenty of resources around for your perusing, and tons of knowledgeable, friendly folks eager to help you if you get stuck along the way. That also means there’s plenty of people working towards constantly improving the React library!
JSX + Virtual DOM
JSX is a nifty little plus in that, while it’s not required, you are able to use it, making the writing and maintaining of your components even more straightforward and easy.
Great Performance
Topping off our list of Pros, we’ve got the Virtual DOM. It opens up the capability of server side rendering, meaning we can take that DOM clone, render it on our server, and serve up some fresh server-side React views. Thanks to Reacts Virtual DOM, pages are quicker and more efficient. The performance gains are quite real when you are able to greatly reduce the amount of costly DOM operations.
Why Not React?
As great as anything is, it can be just as important to know why you SHOULDN’T use it. Nothing is the perfect tool for absolutely everything, so why wouldn’t you use React? Well…
Don’t Use React Where it’s Not Needed
React shines when you’ve got a dynamic and responsive web content to build. If your project won’t be including any of that, React might just not be needed, and could result in you adding a lot of unnecessary code. Another downer is that, if you did opt to avoid pairing JSX in with your react components, your project can get kind of messy and harder to follow.
Understand the React Toolchain
Some people don’t realize that React only represents the View. That means you’ll have to be bringing in other technologies in order to get something fully functioning off the ground. Developers typically recommend using Redux with React, as well as Babel, Webpack, NPM… so if you’re not already familiar with the common accompaniments of React, you could end up biting off a bit more that you want to chew.
So in the end, should you use React? Is the hype train worth jumping on? Well, that’s completely dependent on your project and the constraints involved. It’s something that you and your team will have to decide together. Hopefully after reading this article, you are able to recognize what React is, as well as why you should keep in in mind for the future. If you’re interested in a deeper dive into the subjects discussed here, check out the React site! We hope you were able to take away some good info from this edition of ‘What, Why?’, and if you’re looking for more, be on the lookout for our upcoming post on React-Native!
The Importance of Aligning Business Units and IT Department
During the PNEC conference on May 20-22, 2014, there were multiple presentations showcasing their various level of success in IT and data management projects. One key theme that kept appearing was the topic of “aligning business units with IT departments” for a joint effort of implementation. However, for most of the presentations, there was no further explanation of how to make this happen.
This is an epidemic among multiple industries, but it is particularly severe in the energy space. For many organizations, IT departments work in silos, and business units do not know how to manage them. Read More
SharePoint Trends for 2014
SharePoint is an application platform that allows you to take control of the content and documents that you put on the Internet. Though the capabilities are present in SharePoint for use with external websites (like the kinds that your customers use to find out more information about your business), most companies have been using SharePoint for internal intranets.
SharePoint is great for tasks like collaboration on projects, document sharing and more. There are several trends with regards to SharePoint that you should definitely be paying attention to in 2014. Read More
InfoPath Retirement: The Doctor is In
SharePoint Consulting Prescribes Solutions to Fit Your Business
SharePoint consulting is often not unlike being a doctor. When a patient visits their doctor, she doesn’t assume that penicillin is the fix for everyone who walks in the door. Instead, a cure is recommended based on specific symptoms.
The same goes for our customers. When we first engage with a new company, the SharePoint team spends some time understanding how the business process is lacking. We’ll also ask questions about specific business goals, long term plans, the number of users, and more. Read More
SharePoint 2013 and Large Lookup Lists
SharePoint 2013 and an Unexpected Cost of Large Lookup Lists
SharePoint 2013 can handle very large lists (given a very restrictive set of requirements). There is however one error that slipped through the cracks from the Microsoft SharePoint development team. When the total number of items in a list exceed 20,000 items (mileage may vary); you may lose the ability to use the list as a Lookup Column while maintaining the ability to edit the list item via the default edit form. Read More
Oil and Gas Software: IT is Adapting in a Brave New World
Oil and gas software helps support IT transformation into valued business partner
It’s no secret that the exploration, drilling and production industry is not the same industry it once was, and oil and gas software can provide companies with the new  capabilities they need to respond to the increasingly competitive environment around them. In a recent article from The American Oil & Gas Reporter, titled “IT Leaders Embrace Challenging Transformation In Upstream Operations”, Johnathan Zanger and Gerry Swift discuss how change in the oil and gas industry has created both challenge and opportunity for IT.
capabilities they need to respond to the increasingly competitive environment around them. In a recent article from The American Oil & Gas Reporter, titled “IT Leaders Embrace Challenging Transformation In Upstream Operations”, Johnathan Zanger and Gerry Swift discuss how change in the oil and gas industry has created both challenge and opportunity for IT.
Zanger and Swift argue that oil and gas companies have a choice: they can either look at IT as a necessary but inconvenient utility—that is, they could continue to look at IT the same way they always have—or, they can start looking at IT as a valued partner that can help meet desired business outcomes.
Decision Making and IT
Zanger and Swift analyzed data provided by seven different exploration, drilling and production IT groups to gain a better understanding of how decisions are being made in these organizations, and how these decisions affect the business. The results of the analysis show a number of ways that growing the partnership between IT and line of business can benefit oil and gas companies:
- Improved data management
- Greater customer satisfaction
- More opportunities to innovate
- More well-defined corporate structure
Improved data management
As oil and gas companies change the way they operate, they must also change the way they capture, analyze and apply data. It’s no longer sufficient to gather data just for the sake of gathering data. Successful companies must be able to capture pertinent data that can be directly applied to business operations. Oil and gas software can provide the data management capabilities needed to make this happen.
Greater customer satisfaction
Ensuring customer satisfaction has long been one of the most important objectives of oil and gas IT organizations. However, changes in the oil and gas industry have also altered the meaning of the term “customer satisfaction.” It’s no longer just a matter of meeting business objectives and focusing on customer needs. IT organizations now need to make themselves truly customer-centric, aligning themselves to provide business value, before the customer even has to ask.
More opportunities to innovate
The importance of innovation in the oil and gas industry is well established. What seems to be less clear is the difference between change and innovation. Innovation constitutes a change for the better, that opens a new and more effective way of doing things. Many oil and gas companies have difficulty identifying innovation opportunities, but Zanger and Swift predict that a greater partnership between business and IT would make these opportunities easier to find.
More well-defined corporate structure
In order for IT to support the business effectively, there must be established processes in place to show the alignments and accountabilities of everyone involved with the IT organization. IT organizations can no longer continue to exist in their own little world. In order for IT organization to provide true business value, they must understand their relationship with the business, and be able to collaborate consistently.
One of the key misconceptions that Zanger and Swift try to do away with in their article is that changing IT requires bleeding-edge technological solutions. In reality, the solutions needed to drive greater IT involvement with business processes already exist, and they’re already proven. IT just needs to find new ways to apply these tools, such as oil and gas software, to support their mission.
For more on this topic, read this article on how the IT service model is changing…

Software Selection: Assessing Your Options on the Market
Software Selection and Available Product Offerings
In this software selection series, I have covered how to assess the need for custom software in addition to business drivers. In this third post, I’d like to spend some time covering how to answer a specific question. What percentage of my needs are addressed by available product offerings?
It can be a very obvious choice to go for an off-the-shelf product. You don’t need to hire or manage a custom software team. In addition, the costs for a software product that already exists are often more clear.
Custom software projects can stretch out over many months or even years. Depending on the quality of your team, the end product may not even be what you bargained for.
Existing Software Platforms
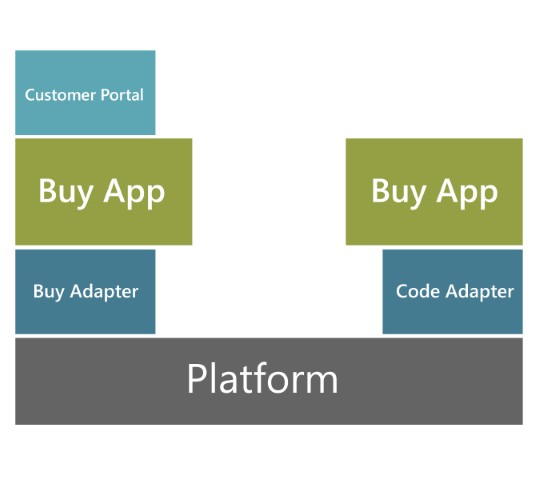 Buying an existing product is no guarantee that you are purchasing all the functionality that your business requires. In the illustration to the right, you can see an example of a platform. This platform provides the baseline of functionality, with applications and a portal bolted on.
Buying an existing product is no guarantee that you are purchasing all the functionality that your business requires. In the illustration to the right, you can see an example of a platform. This platform provides the baseline of functionality, with applications and a portal bolted on.
Many customers come to Entrance and say, “We’re spending $100,000 a year on SharePoint and we’re getting no ROI. What gives?”
What we tell them is that SharePoint only provides the toolbox. Your company needs to be prepared to make the further investment in customization and workflow in order to prove out the true business value of this platform.
The same is the case for many platforms. Before you make the investment in expensive software tools like these, a team that understands your business needs, budget, and resources should make a full evaluation.
When Software is Too Much
By the same token, there will also be times when a given software tool is way overpowered for your company or department’s needs. In this case, it would be a waste of money and resources to buy SAP if only one report was needed.
Doing a full evaluation of the available products in the market for your industry will help your company to see where a simpler option might fit the need very well. This will save your team and the IT staff the time for and money for investing where a larger business problem exists.
For more on the process of software selection, check out this case study for an oil and gas services company!
SharePoint Dashboards: Three Reasons to Build Your One-Stop Shop
Surfacing Vital Information with SharePoint Dashboards
Your Sharepoint dashboard is similar to the dashboard in your car; it contains all the information that is pertinent to your oil and gas operation so you can easily and quickly find what you need. If you haven’t set up your dashboard, it is important to contact a Sharepoint consulting firm to help you get started on this vital task.
The benefits of having your Sharepoint dashboard fully operational are numerous. Here are the basics of the Sharepoint dashboard to help you get an understanding of why it is so important for your oil and gas business.
One-Stop Shop
 Like I said above, the dashboard is your first stop for information, and should contain relevant items that are used by employees for daily functions. You can include so many things on your dashboard, from forms to stock quotes, maps and plans, and even statistics and budget information.
Like I said above, the dashboard is your first stop for information, and should contain relevant items that are used by employees for daily functions. You can include so many things on your dashboard, from forms to stock quotes, maps and plans, and even statistics and budget information.
The dashboard is completely customizable to the needs of your business and to support your daily operations. Your Sharepoint consulting professional can help you determine how you’d like your dashboard to be set up, and what information you need to include.
Drill-Down Menus
The drill-down menu options on the Sharepoint dashboard are one of the most popular among users. You can have many types of drill-downs on your dashboards, with links to information on companies, rigs, wells and assets. Here are a few examples to get your creative juices flowing:
Company –> Field –> Well
Company –> Asset –> Field –> Well
Asset Type –> Field –> Well –> Completion
Area –> Block –> Lease –> Well –> Completion
Plat –> County –> Lease –> Well
As you can see, the options for drill-down menus are endless, and can link to numerous pieces of vital information on current and closed operations.
Filters
Filters are also important when you are setting up your Sharepoint dashboard. You can add filters for operational and non-operational wells. You can also filter by product type, such as oil or gas wells.
Geographical data can be another way to filter information. This allows the user to quickly and easily find the information they need, so they aren’t spending all of their time trying to find what they need to accomplish their mission.
Visualization
Your Sharepoint dashboard also helps users to visualize information so they can gain a better understanding of trends and performance indicators. This will also assist in making business decisions and help further your business reach. You can add charts and graphs to make the information easier to understand and retain.
The Sharepoint dashboard is one of the most important aspects of your Sharepoint site, so it’s important to do it right. Once you have your dashboard set up, it is fairly easy to maintain, and this duty can be handled by an employee in just a few minutes a day.
You will also find that operations run more smoothly when everyone has instant access to the information that they need!
To see how SharePoint dashboards helped one Entrance client accomplish this, check out this case study.
SharePoint Consulting: Library and List Thresholds
SharePoint Consulting Best Practices
Our SharePoint consulting experts have recently run into some problems with SharePoint library and list thresholds that we have been trouble shooting. We’re sharing some of the best practices that we’ve developed as a result to save other users out there some of the trouble!
SharePoint Workflows for Upstream Energy Companies
SharePoint Workflows
Some companies may not realize it, but tools like SharePoint workflows are becoming more and more vital to managing a thriving business. Gone are the days of managing tasks through slips of paper or written work orders.
SharePoint 2013 Troubleshooting: Custom Content Types
SharePoint 2013 Customization
Recently, I was working with a client who just went live on SharePoint 2013. On a sub-site of the home page, there is a document library containing forms and policies. To visually organize the library, I added a choice column called DocType.
Data Management: Information Security for Oil and Gas
Threats to Data Management and Information Security
According to a recent report by Booz Allen Hamilton, one of the big data management concerns for the oil and gas industry is information security. According to the report, oil and gas companies are at a constant threat of being hacked, and there is only so much these companies can do to prepare themselves for this threat.
Business Intelligence Tools: Power BI First Impressions
Business Intelligence and Power BI
This is an exciting time for SharePoint consulting and business intelligence as Microsoft moves more of its offerings into the cloud. The Power BI preview comes with several features for data query, data visualizations, collaboration, and mobility. Additionally there are new add-in components for the Excel client.
Great Custom Software: The Five W’s
Improving Custom Software
This quarter, Entrance is making quality a focus for improvement, both for custom software development and our software consulting efforts. Although we always strive to deliver the best possible result to clients, we know that we can always implement new techniques that will make these results even better.